Fast ARMv6M mempy - Part 6 - Benchmark function
This is the 6th part of "Fast ARMv6M mempy", see other parts you may have missed:
- Part 1 - ASM code
- Part 2 - Options & Results
- Part 3 - Replace SDK memcpy
- Part 4 - Automated case generation
- Part 5 - Test function
- Part 6 - Benchmark function
Full code available at github (test project, only fast ARMv6M mempy).
Function requirements
Following the list to automate the tests:
- Automated generation of files needed to test all cases.
- Create a test function to ensure that all memcpy cases work correctly.
- Create a benchmark function to evaluate the speed of each implementation.
- Create a good compare system.
This was my list of requirements and how I met them:
| Requirement | Implementation details |
|---|---|
| Test all memory spaces. | It tests for RAM, ROM, CACHED FLASH & UNCACHED FLASH. |
| Test aligned and misaligned copy using all possible offset combinations. |
It tests all combinations of [0..3] offsets, for source and destination (16 in total). |
| The impact in timing of the code out of "memcpy" itself must be minimized. |
"memcpy" is called 10 times in a row for each inner iteration and this is repeated 100 times. Measuring precision is better than +-1 cycle for comparisons. |
| Results must be reproducible. | The function is located in RAM to avoid instruction cache misses / waits. Interrupts are disabled for each test. For XIP FLASH, cache is reset before each test. |
| Results must be output in a format easy to process afterwards by other tools. |
Results are printed in columns, first for aligned then unaligned copy, one row for each size. Fields are separated by a tab. |
| Total test time should be reasonable | For big sizes (>84), only 8 sizes out of every 100 are tested, more than enough points to compare / plot the results. |
The output shows cycles used for each call, all the math is already done in the function.
A sample of the output (with tabs replaced with spaces to better suit the web page format):
memcpy_armv6m_test_miwo_1_mssp_1_opxip_1_opsz_1_msup_0
RAM
Size 0-0 1-1 2-2 3-3 0-1 0-2 0-3 1-0 1-2 1-3 2-0 2-1 2-3 3-0 3-1 3-2
0 24.8 24.9 24.9 24.8 24.9 24.9 24.9 24.8 24.8 24.8 24.8 24.8 24.9 24.9 24.9 24.9
1 28.9 28.8 28.8 28.8 28.8 28.8 28.8 28.8 28.8 28.8 28.9 28.9 28.9 28.8 28.8 28.8
...
511 465.8 467.8 469.8 470.9 1346.9 1344.9 1345.9 1338.9 1347.9 1343.9 1336.9 1345.9 1346.9 1339.9 1343.9 1346.9
512 457.8 474.8 469.8 476.8 1350.9 1348.9 1349.9 1336.9 1351.9 1347.9 1334.9 1349.9 1350.9 1337.9 1347.9 1350.9Function implementation
Definitions
The code defines the following 4 test types:
#define MEMCPY_BENCHMARK_MEM_ROM 0
#define MEMCPY_BENCHMARK_MEM_RAM 1
#define MEMCPY_BENCHMARK_MEM_FLASH_WITH_CACHE 2
#define MEMCPY_BENCHMARK_MEM_FLASH_WITHOUT_CACHE 3And only one is selected using this line:
#define MEMCPY_BENCHMARK_MEM MEMCPY_BENCHMARK_MEM_RAMThe following macros define the size of the test memory:
#define ROW_SIZE 512
#define ROW_SIZE_EXTRA (ROW_SIZE + 16)
#define ROW_COUNT 100The test does 100 "rows", each one can be up to 512 bytes in size and can be offset by up to 16 bytes.
#if MEMCPY_BENCHMARK_MEM == MEMCPY_BENCHMARK_MEM_ROM || MEMCPY_BENCHMARK_MEM == MEMCPY_BENCHMARK_MEM_RAM
// Keep ROM access valid for RP2040:
// ROW_SIZE_EXTRA + (ROW_COUNT - 1) * DST_OFFSET_PER_ROW_COPY < 16kb.
// Keep RAM usage low.
#define SRC_OFFSET_PER_ROW_COPY 4
#else
#if PICO_FLASH_SIZE_BYTES > 2 * ROW_SIZE_EXTRA * ROW_COUNT
#define SRC_OFFSET_PER_ROW_COPY ROW_SIZE_EXTRA
#else
#define SRC_OFFSET_PER_ROW_COPY 4
#endif
#endif
#define DST_OFFSET_PER_ROW_COPY 4 // 4 or ROW_SIZE_EXTRA , 4 Keeps RAM usage low.For RAM / ROM or FLASH memory under 51K (2 x ROW_SIZE_EXTRA x ROW_COUNT) the pointer will be moved only 4 bytes after each "row", this keeps the memory buffer under 1Kb without affecting the results.
For "big" FLASH (XIP) it will be moved a whole row (ROW_SIZE_EXTRA), so there will be 0 cache hits, this is the the worst case scenario (Total XIP FLASH required: 51Kb).
There are also some more macros defined depending on the memory type:
#if MEMCPY_BENCHMARK_MEM == MEMCPY_BENCHMARK_MEM_FLASH_WITH_CACHE || MEMCPY_BENCHMARK_MEM == MEMCPY_BENCHMARK_MEM_FLASH_WITHOUT_CACHE
// XIP FLASH is very slow, 1 iteration is good enough
#define TEST_UNROLLED_ITERATIONS 1
#define TEST_SRC_IS_XIP_FLASH 1
#else
#define TEST_UNROLLED_ITERATIONS 10
#endifThe TEST_UNROLLED_ITERATIONS controls how many calls to memcpy will be done "unrolled" (consecutive calls inside the inner loop).
"memcpy_benchmark" implementation
The function starts by defining getting the pointer to the memory to test:
void __not_in_flash_func(memcpy_benchmark)(void)
{
uint32_t t1, t2;
const char * MEMORY_NAME = "";
#if MEMCPY_BENCHMARK_MEM == MEMCPY_BENCHMARK_MEM_ROM
const uint8_t * src = (const uint8_t * )0x8; // ROM
MEMORY_NAME = "ROM";
#elif MEMCPY_BENCHMARK_MEM == MEMCPY_BENCHMARK_MEM_RAM
const uint8_t * src = ramMemoryBuffer;
MEMORY_NAME = "RAM";
#elif MEMCPY_BENCHMARK_MEM == MEMCPY_BENCHMARK_MEM_FLASH_WITH_CACHE
const uint8_t * src = flashMemoryBuffer;
MEMORY_NAME = "FLASH";
#elif MEMCPY_BENCHMARK_MEM == MEMCPY_BENCHMARK_MEM_FLASH_WITHOUT_CACHE
const uint8_t * src = (uint8_t *)((uint32_t)flashMemoryBuffer + (XIP_NOCACHE_NOALLOC_BASE - XIP_MAIN_BASE));
MEMORY_NAME = "FLASH - NO CACHE";
#else
#error "MEMCPY TEST CASE NOT IMPLEMENTED"
#endif
uint8_t * dst = ramDstBuffer;Next, the conversion factor used to convert microseconds to cycles is calculated:
float usToCycles = (float)(clock_get_hz(clk_sys) * (1 / (TEST_UNROLLED_ITERATIONS * ROW_COUNT * 1000000.0)));After that, there are some loops to test all combinations of offsets for each size:
// Repeat for all sizes, size starts at -1 to print headers with the same logic / order
// For this reason, size is of type "int32_t" and not "size_t"
for (int32_t size = -1; size <= ROW_SIZE; size++)
{
// Jumps to make the tests faster, for big sizes, test only 8 sizes out of every 100
if (size == 84)
size = 99;
if (size == 108)
size = 199;
if (size == 208)
size = 299;
if (size == 308)
size = 399;
if (size == 408)
size = 499;
if (size > ROW_SIZE)
size = ROW_SIZE;
if (size >= 0) // Active test row
printf("%" PRIi32, size);
else // Header
printf("Size");
for (int8_t aligned = 1; aligned >= 0; aligned--) // Test aligned data, then misaligned
{
for (size_t srcOffset = 0; srcOffset <= TEST_SRC_OFFSET; srcOffset++)
{
for (size_t dstOffset = 0; dstOffset <= TEST_DST_OFFSET; dstOffset++)
{
if ((aligned == 1) == (srcOffset == dstOffset)) // If offset combination matches the alignment being tested
{
if (size >= 0) // Active test row
{Inside the last "if", the pointers for source and destination are prepared, and interrupts are disabled:
const uint8_t * s = src + srcOffset;
uint8_t * d = dst + dstOffset;
uint32_t h = ROW_COUNT;
// Make sure no interrupts are enabled
uint32_t savedInterruptState = save_and_disable_interrupts();If the test if for XIP FLASH, cache is flushed to start from empty cache each time (worst case):
#if TEST_SRC_IS_XIP_FLASH
xip_ctrl_hw->flush = 1;
xip_ctrl_hw->flush;
while (!(xip_ctrl_hw->stat & XIP_STAT_FLUSH_READY_BITS))
tight_loop_contents();
#endifAnd finally, this is the code that times the calls to memcpy:
t1 = time_us_32();
for (; h > 0; h--)
{
memcpy(d, s, (size_t)size);
#if TEST_UNROLLED_ITERATIONS > 1
memcpy(d, s, (size_t)size);
memcpy(d, s, (size_t)size);
memcpy(d, s, (size_t)size);
memcpy(d, s, (size_t)size);
memcpy(d, s, (size_t)size);
memcpy(d, s, (size_t)size);
memcpy(d, s, (size_t)size);
memcpy(d, s, (size_t)size);
memcpy(d, s, (size_t)size);
#endif
d += DST_OFFSET_PER_ROW_COPY;
s += SRC_OFFSET_PER_ROW_COPY;
}
t2 = time_us_32();After that, interrupt state is restored and the time (in microseconds) is printed:
restore_interrupts(savedInterruptState);
printf("\t%.1f", (float)(t2 - t1) * usToCycles);Benchmark time
Each call to the benchmark function takes between 5.3 and 6.7 s.
So testing all implementation cases takes between 4 and 5 min.
Benchmark data analysis
Following the list to automate the tests:
- Automated generation of files needed to test all cases.
- Create a test function to ensure that all memcpy cases work correctly.
- Create a benchmark function to evaluate the speed of each implementation.
- Create a good compare system.
To accomplish point 4 I needed a compare system with graphs that allows easy comparison among all implementations.
I used a MS Excel document with multiple tabs for this.
Data input
| Tab | Description |
|---|---|
| Data | Tab where all the data output from the benchmarck can be pasted. |
| Implementations | "Test data" table must be filled with the implementation list, with size and hashes, pasted from the test output. |
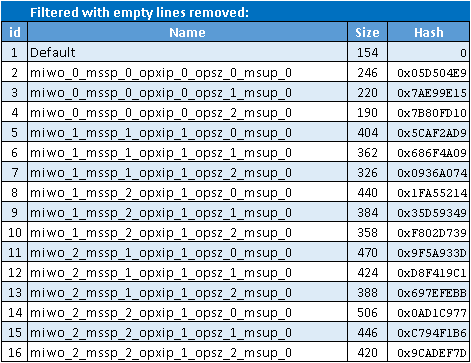
The implementations tab has the filters to reduce the cases to show:

The filtered cases are shown in a table:
Data selection
Tabs that shows the data for each selected implementation:
| Tab | Description |
|---|---|
| Ref | Reference |
| Impl1 | Implementation1 |
| Impl2 | Implementation2 |
To make the data easier to digest (12 curves x 2 implementations to compare are too much), in each tab, the following data is calculated:
Minimum, maximum and average cycles for each size:
For aligned data:
- A. MIN.
- A. MAX.
- A. AVG.
Same for misaligned data:
- M. MIN.
- M. MAX.
- M. AVG.
And finally, the average throughput (in Mb/s)
- Aligned
- Misalign.
For convenience, "Impl1" tab has the dropdown lists to select the implementations and the graphs to plot / compare the cycles & throughput:

Here an example showing the cycles graph (Lower is better):
 .
.
In dashed lines the reference implementation, in solid lines the implementation 1.
In this particular case all misaligned graphs for the reference implementation are overlapped at the topmost line.
Bellow the same case showing the throughput (higher is better):

Heat map with differences in cycles between implementations
| Tab | Description |
|---|---|
| Imp1-Imp2 | Implementation1 - Implementation2 |
| Imp1_Ref_Diff | Implementation1 - Reference |
| Imp2_Ref_Diff | Implementation1 - Reference |
This allows a complete view of cycle differences for all offset cases.
Cold colors means less cycles used (negative diff.) -> GOOD.
Hot colors means more cycles used (positive diff.) -> BAD.
RAM benchmark comparison:

Uncached XIP FLASH benchmark comparison:

The second map shows the cycles lost by changing opsz0 to opsz1 in this specific case.
Note
Notice the RAM comparison shows no jitter, very uniform.
For FLASH there is always a +-1 cycle of jitter, surely something related to the SPI clock divisor.